
Preparación de datos incompletos con Markov Random Fields
Los datos incompletos son un problema recurrente para el aprendizaje automático (Machine Learning). Sin embargo, con la ayuda de un método basado en la probabilidad, las brechas de dichos conjuntos de datos pueden cerrarse para que puedan usarse para un procesamiento posterior. Markov Random Fields o campos aleatorios de Markov.
Los datos son esenciales en el contexto del aprendizaje automático. Sin embargo, en muchos dominios, los registros pueden estar incompletos debido a errores en la medición o el procesamiento. Esto también se puede ver, por ejemplo, en el repositorio de aprendizaje automático de UCI, donde faltan entradas en dos de los cinco conjuntos de datos más populares (“Adult” y “Heart Disease”). Con datos vacíos, el aprendizaje del modelo suele ser difícil y, en algunos casos, imposible. Sin embargo, los métodos generativos pueden ayudar al completar los datos incompletos con las aproximaciones más razonables posibles.
Modelado basado en probabilidad
Las entradas de cada conjunto de datos pueden interpretarse como realizaciones concretas de un vector aleatorio. Debido a la incompletud, los componentes individuales del vector no se observan. Dependiendo del conjunto de datos, también pueden faltar otros componentes de cada entrada. En general, al modelar el vector aleatorio, también se debe tener en cuenta que los componentes individuales pueden ser estadísticamente dependientes entre sí. Estas dependencias se pueden representar bien mediante modelos gráficos probabilísticos, por ejemplo, con campos aleatorios de Markov (Markov Random Fields, MRF).
Con los MRF, las dependencias se describen mediante un gráfico no dirigido. Aquí se supone que las realizaciones del vector aleatorio provienen de un espacio de estado discreto, por lo que primero se deben discretizar algunos conjuntos de datos. Los MRF permiten calcular la distribución de probabilidad multivariada del vector aleatorio. La marginación también permite calcular la probabilidad de varias predicciones para entradas faltantes. Sin embargo, antes de eso, los parámetros del MRF deben determinarse durante el entrenamiento en función de los datos disponibles. Clásicamente, para esto se realiza una estimación de máxima verosimilitud que, sin embargo, requiere datos completamente observados.
Estimación de parámetros con datos incompletos
Afortunadamente, Markov Random Fields también se pueden entrenar con datos incompletos. Para ello se realiza la estimación de máxima verosimilitud según un esquema de maximización de expectativas. En esencia, las partes faltantes del conjunto de datos se completan alternativamente mediante muestreo y luego se vuelvan a estimar los parámetros.
Sin embargo, en el caso de brechas extremadamente grandes en el conjunto de datos, la aleatoriedad del primer paso de expectativa (es decir, el muestreo aleatorio del espacio de estado) puede eclipsar la estimación de los parámetros iniciales. Para contrarrestar esto, se puede derivar conocimiento estadístico de los datos e incorporarlo en la estimación de parámetro en forma de regularización.
Reconstrucción de los datos
La pregunta ahora sigue siendo cómo usar el MRF entrenado para llenar los vacíos en el conjunto de datos con valores significativos. El MRF nos permite calcular la función de probabilidad para ciertas ocupaciones, y así comparar la calidad de diferentes predicciones.
También es posible calcular cuál es generalmente la ocupación más probable, el llamado estado máximo a posteriori (Maximum-a-posteriori, MAP). En el caso de datos incompletos, el estado del MAP está determinado por las observaciones que están parcialmente disponibles. Por lo tanto, las lagunas en el conjunto de datos se pueden cerrar reemplazando todas las entradas faltantes con el pronóstico MAP. Alternativamente, el MRF también se puede usar para calcular la probabilidad de diferentes predicciones y combinarlas si es necesario.
Aplicación en el contexto de los datos satelitales
Las imágenes satelitales sirven como un buen ejemplo de conjuntos de datos incompletos. Han sido una parte integral de la investigación durante años, por ejemplo, en las áreas de cambio climático y estudios de uso de la tierra. Sin embargo, gran parte de la superficie terrestre cubierta por el espacio está cubierta por nubes. En consecuencia, el llenado de lagunas juega un papel importante en el procesamiento de datos satelitales. La siguiente figura muestra cómo se pueden eliminar las nubes de las imágenes utilizando este enfoque.
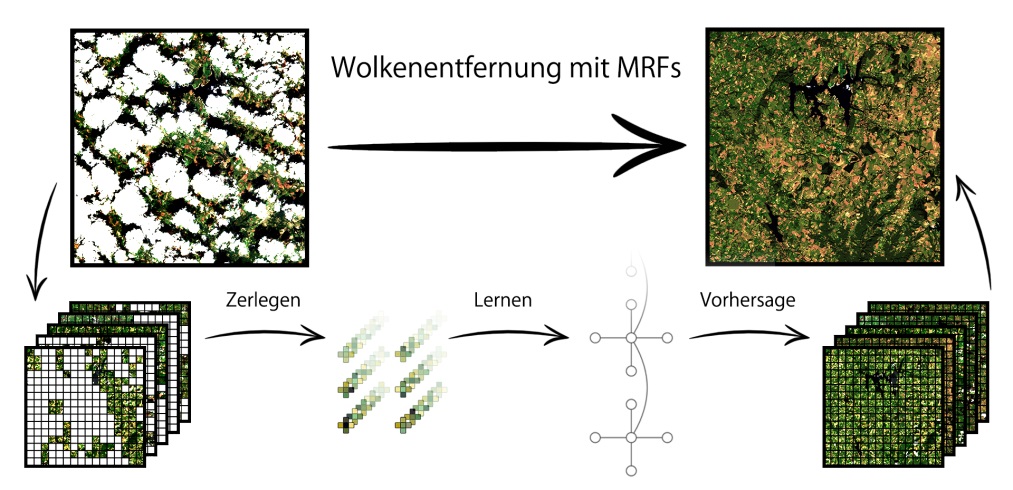
© Raphael Fischer – TU Dortmund
Las imágenes satelitales de la superficie de la Tierra, que está parcialmente oscurecida por las nubes, se pueden reconstruir utilizando modelos basados en probabilidades.
Como se puede ver, los MRF presentados nos permiten reconstruir incluso imágenes muy nubladas. Para los datos satelitales espacio-temporales, tiene sentido modelar solo la vecindad espacial local de los píxeles individuales y “deslizar” el modelo terminado sobre todo el conjunto de datos para su procesamiento. A diferencia de otros métodos, este enfoque no se basa en información adicional y no se hacen suposiciones sobre los datos disponibles. Para mejorar la predicción de imágenes muy nubladas, el conocimiento empírico previo puede derivarse directamente de los datos y tenerse en cuenta durante el entrenamiento en forma de regularización. En los experimentos, las predicciones basadas en MRF para partes nubladas son mucho mejores que las reconstrucciones de otros enfoques. Esto también se refleja en la comparación visual.
Más información en el artículo relacionado:
No Cloud on the Horizon: Probabilistic Gap Filling in Satellite Image Series
Raphael Fischer, Nico Piatkowski, Charlotte Pelletier, Geoffrey Webb, François Petitjean, Katharina Morik. IEEE International Conference on Data Science and Advanced Analytics (DSAA), 2020, PDF.
DSAA 2020: No Cloud on the Horizon: Probabilistic Gap Filling in Satellite Image Series
Fuente: