

Aprendizaje profundo: ¿cómo funcionan las redes neuronales profundas?
Muchos programas informáticos ahora utilizan aprendizaje automático (Machine Learning) e inteligencia artificial (IA). Entienden el lenguaje hablado, pueden interpretar textos, reconocer objetos en fotografías o apoyarnos en asistentes personales. A diferencia de los sistemas técnicos anteriores, sus reacciones no están programadas individualmente, sino que aprenden de los ejemplos.
¿Cómo funcionan las redes neuronales profundas?
En el artículo “¿Cómo aprenden las máquinas?” ya se mostró cómo se puede adaptar un programa de ordenador a los datos para que reacciones de una forma determinada. Se formula un llamado modelo, que recibe una entrada y calcula una salida. Según la pregunta, la entrada puede ser, por ejemplo, una imagen formada por píxeles, una secuencia de tonos en un mensaje de voz o un texto formado por palabras y letras. Esta entrada se convierte en una serie de números (representados como un vector) que luego procesa el modelo. La salida de un modelo es nuevamente un vector de números que describe el resultado deseado. Por ejemplo, puede ser el objeto reconocido en la imagen, el texto del mensaje de voz o la traducción de un texto de entrada a otro idioma. Además, hay un vector de parámetros del modelo que especifica en detalle cómo se asigna la entrada a la salida. En este artículo queremos explicar por qué el aprendizaje profundo a menudo logra una mayor precisión que los métodos tradicionales de aprendizaje automático en aplicaciones complejas.
Las redes neuronales aprenden según el modelo de la naturaleza
El punto de partida para el aprendizaje profundo fue el desarrollo de redes neuronales. Basado en el funcionamiento de una célula nerviosa humana (de ahí el término “redes neuronales”), en la década de 1950 se formuló un primer modelo cuyo comportamiento de entrada/salida puede ser entrenado. Se calcula una suma ponderada de las entradas, con los pesos correspondientes a la fuerza de conexión entre las células nerviosas. Si se interpreta un valor de salida mayor de cero como clase A, y un valor menor que cero como clase B, se puede este modelo para resolver problemas de clasificación. La base para la predicción es un conjunto de ejemplos de entrenamiento, cada uno de los cuales consta de un vector de entrada y una salida asociada. Los pesos dentro de la red neuronal se cambian mediante métodos de optimización de tal manera que predicen las clases para todos los ejemplos de entrenamiento de la mejor manera posible. Este modelo de una red neuronal simple de un nivel se llama perceptrón (más en el estudio sobre perceptrones).
Aquí consideramos un ejemplo de aplicación simple con solo dos entradas.
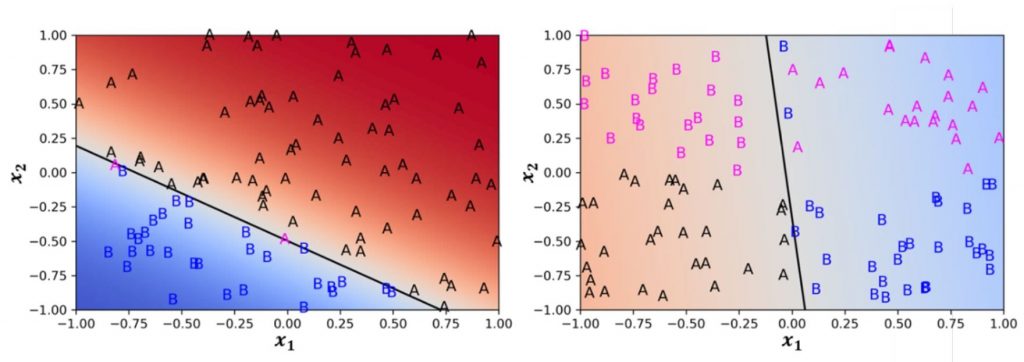
En el gráfico del lado izquierdo de la figura, a las dos características de entrada se les asigna una clase A o B. Como puede verse, un perceptrón siempre crea una línea divisoria recta (generalmente un hiperplano) en el espacio de entrada. El perceptrón entrenado puede separar muy bien las dos clases, por lo que solo se asignan incorrectamente dos ejemplos (magenta). En el lado derecho, los ejemplos de entrenamiento de las dos clases están dispuestos “en cruz” para el “problema XOR”. Aquí el perceptrón simple no puede encontrar una buena línea divisoria.
El perceptrón de dos niveles resuelve el problema XOR
Pasó más de una década antes de que se presentara una solución al problema XOR. Para ello es necesario ampliar el perceptrón simple. En primer lugar, se calculan varias sumas ponderadas de forma diferente a partir de las entradas, que luego se transforman mediante una función creciente no lineal, por ejemplo, tanh. Los resultados se denominan unidades ocultas porque no hay valores observados para estas variables en los datos de entrenamiento. Sirven como entrada para otro perceptrón, cuya salida nuevamente predice la clase.
Los cuatro pilares de las redes neuronales profundas
Las redes neuronales profundas para el procesamiento del lenguaje natural, el reconocimiento de objetos en imágenes y el reconocimiento de voz tienen una arquitectura especializada con capas adaptadas a cada aplicación. Hoy en día, a menudo logran precisiones en el reconocimiento de objetos y procesos que son tan buenas o mejores que las de los humanos. Por lo general, tienen de docenas a cientos de capas y forman el núcleo del área de investigación Deep Learning. En general, su éxito se basa en cuatro pilares:
- la disponibilidad de potentes procesadores paralelos para realizar el entrenamiento,
- la recopilación y anotación de extensos datos de entrenamiento,
- el desarrollo de potentes métodos de regularización y optimización, y
- la disponibilidad de kits de herramientas que definen fácilmente redes neuronales profundas y calculan sus gradientes automáticamente.
Fuente:
¿Cómo funcionan las redes neuronales profundas?