
Aprendizaje automático: asignación automática de palabras clave para textos cortos
Las bases de datos con extensas colecciones de texto, como noticias, publicaciones o patentes, suelen ser confusas simplemente por la cantidad de documentos que contienen. Por lo tanto, durante mucho tiempo ha sido costumbre proporcionar textos guardados con palabras clave que permitan una búsqueda rápida y específica. En el pasado, esto se hacía asignando manualmente las palabras clave. Sin embargo, este es un proceso costoso y que lleva mucho tiempo, porque los empleados (anotadores) responsables de asignar palabras clave deben estar bien versados en los temas tratados. Incluso si tales expertos están disponibles, en algunos casos el resultado no es óptimo: los expertos pueden usar diferentes términos para nombrar el mismo tema. Si, por el contrario, se trabaja con una lista controlada de palabras clave por razones de uniformidad, debemos mantenerla a un gran coste para hacer justicia a los nuevos temas. (Similitudes semánticas en aprendizaje automático)
Por lo tanto, hemos abordado la cuestión de cómo los textos breves, por ejemplo, informes de una agencia de noticias o resúmenes de publicaciones y patentes, pueden proporcionarse automáticamente con palabras clave relacionadas con el contenido. Dicho procesamiento se denomina “etiquetado” en la jerga técnica.
Parar comprender mejor esta tarea, conviene tener claros los posibles objetivos del etiquetado: las palabas clave (etiquetas) deben representa los temas principales del texto de un vistazo. Es importante que las palabras clave estén en un contexto más amplio. Esto significa que las palabras clave seleccionadas también deben aparecer en otros textos sobre temas similares. Por lo tanto, es bastante inapropiado seleccionar un término que sea muy específico o demasiado general. Los enfoques de “nube de palabras” y “modelos de temas” que se presentan como ejemplos en las siguientes dos secciones cumplen estas condiciones más o menos bien, y tienen ventajas y desventajas específicas.
Nubes de palabras
Las nubes de palabras fueron muy populares en la Web 2.0 en la primera década del milenio. La selección de palabras se logró mediante estadísticas simples de conteo. Las nubes de palabras se basan en una gran cantidad de textos (término técnico: el corpus). Las palabras de la nube que realmente aparecen en uno de los textos se pueden usar como etiquetas para este texto. La ventaja es el algoritmo muy simple. Una desventaja es la falta de referencia al contexto y propósito de los textos, y el significado a menudo cuestionable de las palabras identificadas. Por lo tanto, se recomienda una limpieza posterior de nubes de palabras para eliminar las palabras funcionales u otros términos sin sentido que aparecen con frecuencia. Un ejemplo frecuentemente citado es el predominio del término “http” en un corpus que consta de archivos codificados en HTML. Otra desventaja surge del problema de que al texto que no contiene ninguna de las palabras de la nube de palabras no se le pueden asignar etiquetas.
Modelos de tema
Unos años más tarde, los modelos temáticos se basaron en una base teórica mucho más compleja. Los temas se entienden aquí como “sujetos” que se tratan en los textos. El algoritmo LDA (Latent Dirichlet Allocation) se utilizó con especial frecuencia como modelo temático. En este método de agrupación de textos, se establece una relación entre los textos de un corpus, las palabras contenidas en los textos y los temas “invisibles” (latentes) sobre la base de una distribución de probabilidad. Los temas latentes se caracterizan por palabras que probablemente aparecerán en textos que traten sobre este tema. Los propios textos también se asignan a los temas con probabilidades. Esto tiene sentido, porque un texto puede tener relación con varios temas. Para el etiquetado de un texto, ahora se pueden usar las palabras de los temas, que representan los temas del texto con una alta probabilidad. Una ventaja sobre la nube de palabras es la capacidad de asignar palabras clave centradas en temas de sus temas a cada texto. Sin embargo, el problema de los términos sin sentido como “http” también existe aquí.
Etiquetado semántico
En base a esta situación, hemos desarrollado una cadena de procesamiento de varias etapas (Workflow, flujo de trabajo) para evitar o compensar las desventajas de los enfoques anteriores. Nos basamos en el enfoque de vectores incrustados de palabras, que se ha desarrollado a pasos agigantados en los últimos años. El algoritmo más conocido para calcular vectores de incrustación es Word2Vec. Los vectores de incrustación de palabras se pueden utilizar para inferir similitudes semánticas entre términos sin interpretación humana. Esta propiedad se conoce desde hace varios años, comenzando con las publicaciones sobre el algoritmo Word2Vc. En base a esto, se desarrolló el programa “StarSpace” (explicación y código del programa). StarSpace calcula incrustaciones para entidades. El procedimiento funciona para palabras y textos, y también para metadatos que describen textos, por ejemplo, categorías de texto, palabras clave, nombres de autores, etc.
Nuestro enfoque consiste en recopilar primero palabras clave candidatas de los textos individuales en un corpus. Para hacer esto, usamos un algoritmo simple completamente automático. Aquí llevamos el término palabra clave un poco más allá, y también recopilamos frases que pueden constar de varias palabras y que llamamos términos clave. Para un corpus grande, aquí se reúnen varios miles, o incluso decenas de miles, que luego se filtran en dos pasos. Primero, determinados el contenido de la información en relación con el corpus para cada parte de un término clave, es decir, cada palabra individual, utilizando estadísticas basadas en el conteo de la teoría de la información. Esto nos permite eliminar todas las frases que no contienen una palabra con alto contenido de información. Las frases restantes luego se ordenan de acuerdo con la alta frecuencia de su aparición en los textos y se retienen las frases contadas con mayor frecuencia. StarSpace permite aprender varios miles de términos clave para grandes corpus.
Aprender aquí significa que los términos clave, como las categorías de un sistema de clasificación de modelos de StarSpace, se asignan a los textos en los que realmente aparecen. El efecto que usamos para el etiquetado es que los términos clave aprendidos también se asignan a nuevos textos en los que no aparecen textualmente, pero que son similares en contenido (semántica) a los textos del corpus de aprendizaje. StarSpace utiliza la propiedad conocida del algoritmo Word2Vec para codificar la similitud semántica en vectores de incrustación de palabras, también para los vectores de los términos clave.
Etiquetado de resúmenes de patentes
Hemos profundizado en el ejemplo del etiquetado de resúmenes de patentes. La figura 1 muestra un resultado parcial. Los términos clave se extrajeron de un corpus muy grande de resúmenes de patentes.
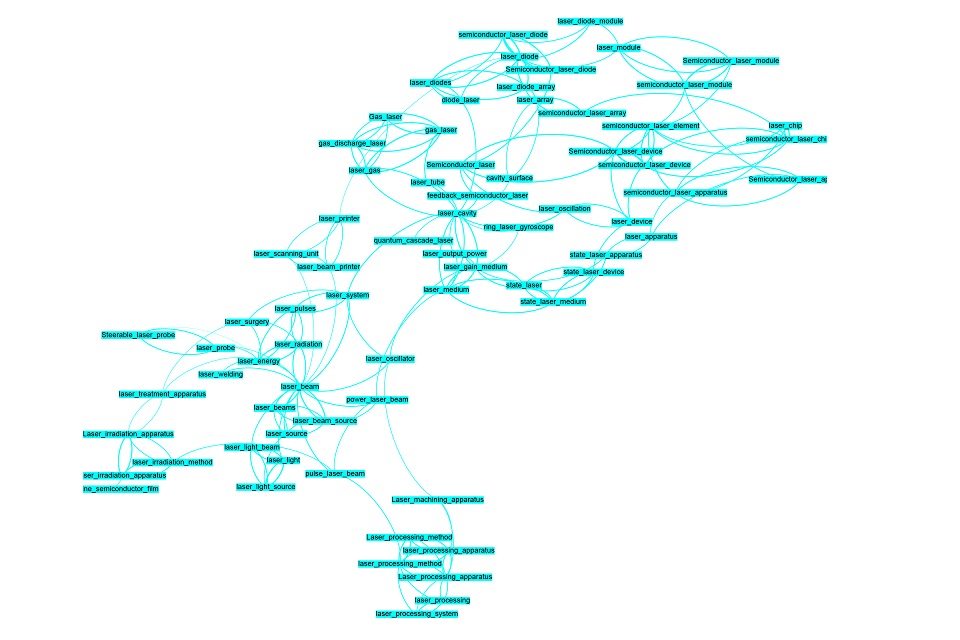
Figura 1: Similitudes semánticas de términos clave extraídos automáticamente de resúmenes de patentes sobre el tema de la tecnología láser
Similitudes semánticas en aprendizaje automático
Aquí se muestran términos del campo de la tecnología láser. Técnicamente, la línea de conexión entre dos términos significa que los vectores de inserción de palabras de esos términos son muy similares. En términos de contenido, significa que los términos del corpus se usan en contextos similares (en relación con otros términos y palabras en general). Por lo tanto, se puede suponer una similitud semántica de los términos. Nuestro enfoque ofrece dos resultados esenciales: los términos clave extraídos del corpus están en una relación se similitud semántica, que se puede visualizar y proporciona una descripción general rápida de los temas de una colección de texto. Con los parámetros aprendidos del modelo StarSpace, también se pueden asignar palabras clave adecuadas a nuevos textos relacionados temáticamente, incluso si no aparecen en los textos.
Fuente:ML2R