

Antes de comenzar con el aprendizaje automático, existen posibles preguntas abiertas que deben aclararse: ¿Cómo aplico el aprendizaje automático en la práctica? ¿Qué herramientas son adecuadas para mi pregunta? ¿Y dónde puedo encontrar más información sobre cómo usar ML en la práctica? Esta contribución de la vida cotidiana de los investigadores de ML2R es parte de la serie “Fundamentos de Machine Learning” y pretende proporcionar una introducción a la práctica e información sobre recursos adicionales. Te explicamos cómo hacerlo en tres pasos.
Paso 1: Mentalidad
El aprendizaje automático probablemente se asocie primero con la experiencia avanzada en matemática y programación, pero el aprendizaje automático se ha vuelto más accesible, incluso sin mucha experiencia en programación o un título en matemáticas. Un agricultor de hortalizas de Japón lo demuestra. Makoto Koike ha automatizado el proceso de clasificación de pepinos utilizando una plataforma ML. Su base: un fuerte interés y 7.000 imágenes de pepino. Pero, ¿qué se necesita para usar el aprendizaje automático de forma independiente?
De manera realista, se necesita cierta comprensión de cálculo, álgebra lineal y programación para ir más allá del “campo base” y aplicar más que una regresión logística a un conjunto de datos básico. Estamos convencidos de que esta comprensión básica se puede lograr con los recursos y el tiempo adecuados. Hemos reunido una pequeña selección de recursos accesibles al final del artículo. Más bien, queremos enfatizar aquí en primer lugar que la actitud juega un papel importante y enfatizar dos puntos:
- El aprendizaje automático no es magia.
Es una ilusión obtener los resultados deseados con solo presionar un botón. El 80% del trabajo está en la aplicación, especialmente en la preparación de datos. Debes estar preparado para esto para no tener falsas expectativas.
- El aprendizaje automático es una herramienta.
Detrás de la aplicación siempre hay un problema que necesita ser resuelto. A veces, la mejor solución para esto es un enfoque simple basado en reglas u operativo. Cada enfoque tiene diferentes herramientas que deben elegirse adecuadamente.
Paso 1 en una frase: Dominar el aprendizaje automático es factible y es importante ser realista con respecto a los objetivos.
Paso 2: Estructura
Se requiere un proceso sistemático para soluciones robustas y relacionadas con la aplicación. Incluso para proyectos pequeños, vale la pena seguir un proceso para no caer en un callejón sin salida. Un proceso puede desarrollarse a través de prueba y error, o uno puede orientarse a procesos estandarizados existentes. El Ciclo CRISP-DM (Cross Industry Standard Process for Data Mining) es un proceso que forma un buen marco, y que casi siempre usamos en proyectos.
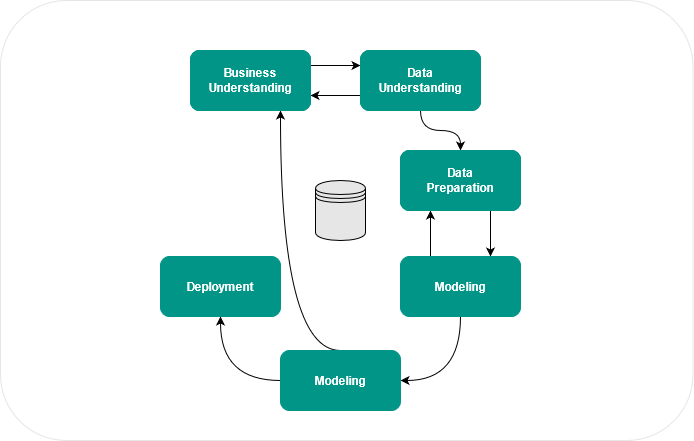
El CRISP-DM consta de las siguientes seis fases:
- Comprensión empresarial (Business Understanding) – Identificación del problema.
- Comprensión de los datos (Data Understanding) – Recopilar y explorar datos.
- Preparación de los datos (Data Preparation) – Preprocesamiento de datos.
- Modelado (Modelilng) – Seleccionar métodos, entrenar y probar el modelo.
- Evaluación (Evaluation) – Verificar el resultado en función de la tarea.
- Implementación (Deployment) – Informe, integración de modelos, etc.
El proceso es flexible en la ejecución. Por ejemplo, puede suceder fácilmente que en la fase de Evaluación uno encuentre que los resultados aún no corresponden al objetivo. En este caso, salte a la fase de Comprensión empresarial para explorar otras opciones, como si hay más datos disponibles para usar para mejorar los modelos. El proceso sirve para identificar obstáculos en una etapa temprana: ¿Están disponibles los datos o tienen que obtenerse o, incluso, generarse primero? ¿La calidad de los datos es suficiente? ¿La calidad de este modelo cumple con los requisitos? Con un proceso claro, estas preguntas se pueden aclarar a tiempo.
Paso 2 en una frase: Un proceso facilita la aplicación.
Paso 3: Herramienta
Para salid del “campo base”, se necesita la herramienta adecuada, además del enfoque y el proceso correctos. Las herramientas de ML van desde editores hasta lenguajes de programación, pasando por entornos de desarrollo y herramientas de Business Intelligence. En principio, cualquier lenguaje de programación puede usarse para aplicaciones ML. Algunos lenguajes de programación ofrecen bibliotecas adecuadas y, por lo tanto, facilitan la implementación. Si tenemos poca experiencia en programación, las siguientes herramientas son adecuadas para comenzar: WEKA (código abierto), RapidMiner (todoterreno) y KNIME (especialmente para minería de datos).
Lenguajes de programación: según GitHub, Python es el lenguaje de programación más utilizado en el campo de ML. C++ está en segundo lugar y JavaScript y Java están en tercer y cuarto lugar.
- Python
- C++
- JavaScript
- Java
- C#
- Julia
- Shell
- R
- TypeScript
- Scala
Entornos de desarrollo: Se recomienda un entorno de desarrollo para todo lo que vaya más allá de las simples pruebas. Según un informe de Kaggle, el entorno de desarrollo más popular es JupyterLab, seguido de Visual Studio Code y PyCharm.
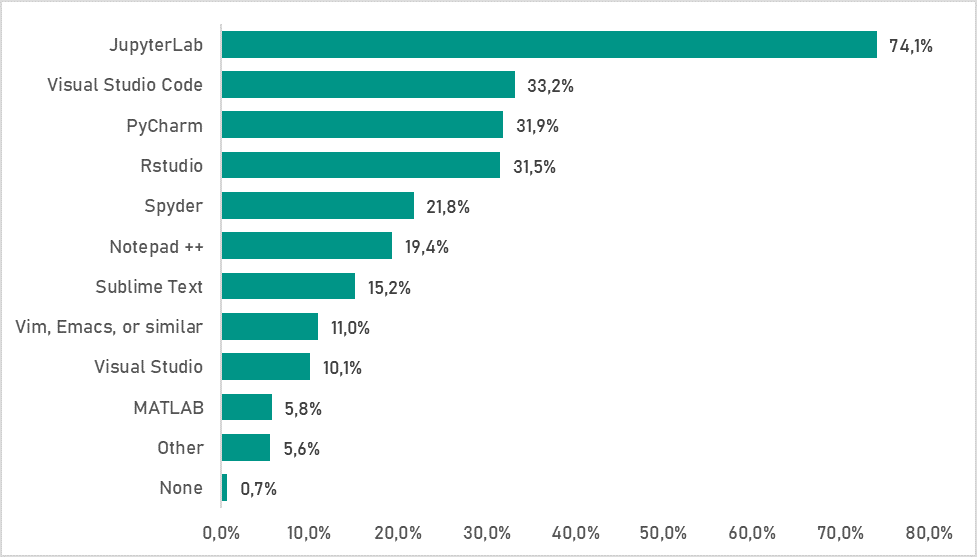
Los resultados de la encuesta de Kaggle sobre qué entornos de desarrollo utilizan los encuestados.
La Library Fundament
Una vez que hayamos elegido un entorno de desarrollo, algunos lenguajes de programación ofrecen bibliotecas adecuadas. A continuación, entraremos en las bibliotecas populares de Python que también se usa en el contexto de ML2R.
- Pandas – Para procesamiento de datos, útil para editar “DataFrames” y leer y archivos csv.
- NumPy – Para Arrays y Matrices.
- SciPy – Para cálculos como multiplicación de matrices y funciones de optimización.
- Scikit-Learn – Para algoritmos clásicos (clasificación, regresión, clustering, reducción de dimensionalidad).
- TensorFlow y PyTorch – Para redes neuronales profundas.
Herramientas específicas de la aplicación
Según la aplicación y la complejidad, se requieren herramientas adicionales. La visualización es una tarea esencial de un científico de datos y sirve para (a) aclarar las propiedades de los datos de entrada y (b) hacer que los resultados de un algoritmo de ML sean más tangibles. Se recomiendan matplotlib y plotly para la visualización. Además, streamlit ofrece la posibilidad, por ejemplo, de crear rápidamente una aplicación. OpenCV es esencial para el análisis de datos de imágenes, mientras que SpaCy se recomienda para el análisis de datos de texto. Si ya se puede estimar que se crearán muchas versiones del modelo, vale la pena considerar MLFlow. Y si se tiene que lidiar con grandes cantidades de datos, Apache Spark es un buen punto de partida como marco para la computación GPU y el procesamiento paralelo de datos. Las bibliotecas mencionadas ofrecen un punto de partida y representan solo una pequeña parte de la oferta total. Para más requisitos, encontraremos rápidamente lo que estamos buscando en la abundancia de la biblioteca.
Paso 3 en una frase: La herramienta adecuada es relevante para el objetivo.
El camino a la aplicación ML
Después de leer esta publicación, no olvidemos los siguientes tres pasos:
- Paso 1: Es posible dominar el aprendizaje automático y es importante ser realista con respecto a los objetivos.
- Paso 2: Un proceso facilita la aplicación.
- Y el Paso 3: La herramienta correcta es relevante para el objetivo.
En tres pasos, es decir, con la mentalidad, un proceso y la herramienta adecuada, estaremos preparados para ingresar en el campo de juego de ML. Entonces, solo queda una cosa por hacer: ¡comenzar! Hay numerosos recursos disponibles online para aprender y probar más.
Aquí hay una breve colección de recursos adicionales útiles:
- Cómo empezar (la base para el enfoque de arriba hacia abajo presentado): Step-by-Step Guides
- Libros: incluidos los mejores libros gratuitos de ciencia de datos y los mejores libros de texto de aprendizaje automático para científicos de datos.
- Formación y cursos: MOOC, por ejemplo, Coursera y Udemy.
Cursos de formación para científicos de datos
Fuente:
Aprendizaje automático en la práctica